
SSONG Cloud
머신러닝기반 빅데이터 응용 전문가과정 - 14 본문
(2020.07.20)
오늘은 오전과 오후 모두 선형모델에 대해 배웠다.
선형모델을 학습하는 것은 y = wx + b 함수를 찾아내는 것으로
w와 b를 알아내는 것이라 볼 수 있다.
선형모델으로 advertising분석한것 쓰기
오후에는 더 많은 특성을 가지고 있는 bike_demand 자료를 분석하는 활동을 했다.
이 train 데이터는
datatime, season, holiday, workingday, weather, temp, atemp, humidity, windspeed, casual, registered,count로 구성되어 있고 자세한 설명은 다음과 같다.
① datatime = 날짜
② season = 계절(1-봄 / 2-여름 / 3-가을 / 4-겨울)
③ holiday = 공휴일(1-공휴일 / 0-비공휴일)
④ workingday = 일하는 날(1-일하는날 / 0-쉬는날)
⑤ weather = 날씨
(1-맑음,약간구름,부분구름 / 2-안개+흐림, 안개+끊어진구름, 안개+약간구름, 안개 /
3-적은눈, 적은비+뇌우+흩어진구름, 적은비+흩어진구름 /
4-폭우+우박+뇌우+안개, 눈+안개)
⑥ temp = 섭씨 온도
⑦ atemp = 체감 섭씨 온도
⑧ humidity = 상대 습도
⑨ windspeed = 풍속
⑩ casual = 등록되지 않은 사용자 렌탈수
⑪ registered = 등록된 사용자 렌탈수
⑫ count = 렌탈 수요량
여기서 y값은 casual, registered, count로 볼 수 있는데
count는 casual과 registered의 값을 합친 것이다.
또한 이 3가지 컬럼은 train데이터에만 존재하고 test데이터에는 존재하지 않는다.
따라서 머신러닝 과정에 따라 각 활동을 수행해보면 첫번째는 데이터 수집으로 data collection이다.
이 활동에서는 데이터를 수집하고 결측치를 확인하고 채워나갈 수 있다.
하지만 이 데이터에서는 결측치가 없기 때문에 따로 채우는 활동은 하지 않았다.
그리고 info함수나 describe함수를 통해 데이터에 대한 정보를 살펴볼 수 있다.
두번째 과정은 Data preparation으로 데이터를 전처리하는 과정이다.
이번 데이터에서는 train과 test를 한꺼번에 처리하기 위해 all_data라는 변수를 만들어
train과 test를 연결시켜 넣어준다.
all_data = pd.concat([train, test], join = inner)그 후 datetime의 데이터를 년, 월,일,시,분,초,요일로 나눠주는 처리 과정을 거친다.
train['year'] = train['datetime'].dt.year
train['month'] = train['datetime'].dt.month
train['day'] = train['datetime'].dt.day
train['hour'] = train['datetime'].dt.hour
train['minute'] = train['datetime'].dt.minute
train['second'] = train['datetime'].dt.second
train['dayofweek'] = train['datetime'].dt.dayofweek
all_data['year'] = all_data['datetime'].dt.year
all_data['month'] = all_data['datetime'].dt.month
all_data['day'] = all_data['datetime'].dt.day
all_data['hour'] = all_data['datetime'].dt.hour
all_data['minute'] = all_data['datetime'].dt.minute
all_data['second'] = all_data['datetime'].dt.second
all_data['dayofweek'] = all_data['datetime'].dt.dayofweek
그리고 EDA를 수행하는데 여기서 각각의 특성들이 y값에 영향을 미치는 중요한 요소인지 확인하기 위해
여러가지 차트를 그려보는 활동을 하였다.

먼저 (1,1)차트는 year와 count사이의 관계를 나타낸 차트이다.
이 차트를 통해서는 year는 2011년에 비해 2012년이 늘어난 것을 바탕으로 어느정도 영향을 끼칠것이라고
생각해볼 수 있다. 따라서 year을 중요한 특성으로 고려해볼 수 있다.
(1,2)차트는 month와 count 사이의 관계를 나타내는 차트이다.
이 차트를 보면 month에 따라 count값이 어느정도 변화를 보이고 있음을 알 수 있고
따라서 month가 중요하게 영향을 미치는 요소일 것이라 예측해 볼 수 있다.
(2,1)차트는 day와 count의 차트이다.
이 차트를 보면 day에 관계없이 거의 count가 고르게 나타나는 것을 볼 수 있다.
따라서 day는 count에 크게 영향을 미치지 않을 것이라 예측해볼 수 있다.
(2,2)는 hour과 count 관계를 나타내는 차트이다.
이 차트를 보면 hour에 따라 count가 큰 변화를 이루고 있음을 볼 수 있다.
그리고 예측해보면 주로 출퇴근시간에 사용량이 급증하는 것이라 예측해볼 수 있다.
따라서 hour도 count에 영향을 주는 중요한 특성으로 생각해볼 수 있다.
그 후 dayofweek도 count와 관계를 살펴보면 거의 균등하게 나오기 때문에
중요하지 않는 특성이라 생각해 볼 수 있다.

그 다음으로 season에 대해 생각해볼 수 있다.
그런데 이 데이터에서는 계절을 숫자로 나타내고 있기 때문에 잘 알아보기 힘들다.
따라서 다음과 같은 과정을 거쳐 각 숫자를 계절이름으로 매핑해 볼 수 있다.
train['season'] = train['season'].map({1:'Spring',
2:'Summer',
3:'Fall',
4:'Winter'})
all_data['season'] = all_data['season'].map({1:'Spring',
2:'Summer',
3:'Fall',
4:'Winter'})
이 코드를 실행시킨 후 count와의 관계를 살펴보면

여름과 가을은 사용량이 높은데 반해 Spring은 떨어지는 모습을 볼 수 있다.
따라서 season도 count값에 영향을 주는 중요한 요소로 생각해 볼 수 있다.
그 다음으로 holiday 특성에 대해 살펴보면
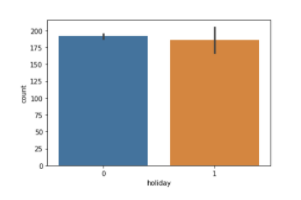
위 그래프와 같은 관계를 갖는다. 이 그래프로 판단해보면 이전에 보았던 count에 별로
영향을 주지 않는 요소라고 생각할 수 있다.
하지만 분산부분을 자세히 보면 0일때와 1일때가 큰 차이를 가지고 있다는 ㄴ것을 관찰할 수 있다.
따라서 이를 자세히 보기 위해 boxplot을 그려보면 다음과 같다.

이에 대해 분석해 보면 holiday값이 0일때 이상치인 값들이 많다는 것을 볼 수 있다.
따라서 holiday또한 중요한 요소로 생각해볼 수 있다.
다음으로 workingday와 dayofweek를 보면 다음과 같다.

먼저 workingday의 경우 barplot은 큰 차이를 보이지 않는다.
하지만 boxplot의 경우에는 범위를 벗어나는 샘플들의 차가 큰 것으로 판단해 볼 수 있다.
따라서 조금 더 자세히 들여다 봐야겠다는 생각이 들 수 있다.
따라서 pointplot으로 그려보면 다음과 같다.

위에서는 그 차이가 드러나지 않았지만 workingday의 여부에 따라 시간으로
나누어보면 count에 있어 큰 차이가 있는 것을 발견할 수 있다. 따라서 workingday도
중요한 특성으로 분류해볼 여지가 있다.
그리고 dayofweek의 경우에도 hour과 연관시켜 pointplot으로 나타내보면 다음과 같다.

이는 workingday에서 요일과 연관시켜 보면 그 공통점을 발견할 수 있다.
먼저 토요일,일요일의 경우 workingday가 0인 날이므로 그때와 비슷한 모습의 선으로 나타내어지고
평일의 경우는 workingday가 1인날과 유사한 형태로 나타내지는 것을 볼 수 있다.
하지만 이 중에서도 금요일과 월요일이 조금 더 높은 count를 갖는 것을
발견할 수 있다.
그 다음은 weather을 살펴보는데 weather는 총 4가지로 분류된다.
맑은 날씨에서 나쁜 날씨로 간다고 하면 그 순서는
clear, cloudy, lightrain, heavyrain으로 나타내어진다.
이를 그래프로 나타내면 다음과 같다.

그런데 이 차트를 보면 이상한 느낌이 들 수 있다.
우리가 상식적으로 생각해보면 맑은날 가장 렌탈 수가 많고 그다음은 구름낀날
비가 조금오는날 폭풍우 치는날 순으로 점점 줄어들 것이라는 느낌이 들텐데
이 차트에 따르면 clear,cloudy,lightrain순으로 줄어들지만 heavyrain이 갑자기 많아지는 것을 볼 수 있다.
따라서 이 부분을 더 살펴봐야겠다는 생각을 할 수 있고,
boolean indexing을 통해 자세히 살펴보면 이 날씨에 대한 데이터가 한개 나오고
잘못 표기되었을 것이라는 생각이 들게 된다.
그래서 이 날짜에 대한 날씨를 임의로 lightrain으로 수정하여 데이터를
처리해볼 수 있다.
train["weather"] = train["weather"].replace(4,3)그 후에 다시 차트를 만들어 보면 예상했던 것처럼 나오는 것을 볼 수 있다.

따라서 weather의 경우도 count에 대해 영향을 미치는 것을 관찰할 수 있으므로 중요한 특성으로
따로 분류할 수 있도록 한다.
그 후 각 특성에 대해 상관관계를 보여주는 heatmap을 통해 각각의 특성간의 가지는 상관관계를 관찰해 볼 수 있다.
train_corr = train.loc[:,:'count'].corr()
plt.figure(figsize=(12, 12))
ax = sns.heatmap(train_corr, annot=True, linewidth=.5)
bottom, top = ax.get_ylim()
ax.set_ylim(bottom + 0.5, top - 0.5)
이를 보면 count와 registered, casual은 거의 1의 관계를 갖는 것을 볼 수 있는데
그 이유는 count는 registered와 casual의 합으로 이루어지기 때문이다.
그 후에 계속해서 특성과 count간의 관계를 살펴보면 temp의 경우
기온을 말하고 atemp의 경우 체감 온도를 말한다. 따라서 서로는 비슷한 특성이기 때문에
하나를 제외시킬 수 있다. 이렇게 하는 이유는 비슷한 특성이 있는 경우 과대적합이 되기
쉽기 때문이다. 따라서 atemp를 제외하고 temp만 고려하고자 한다.
따라서 temp가 count를 이루는 casual과 registered에 미치는 영향을 다음과 같이 차트를 통해 보고자한다.

이 경우 두가지 경우의 차이가 심한 것을 볼 수 있는데 그이유는
등록된 사람이 훨씬 많고 등록되지 않은 사람이 적기 때문으로 볼 수 있다.
따라서 이를 정규화하여 보고자 한다.
이 때 이 활동을 표준 스케일링이라 한다.
각 모델에 대해 스케일리의 효과를 말해보면 다음과 같다.
① knn : 스케일링 했을 때 성능 향상
② 선형모델: 스케일링 했을 때 점수향상이 있을수도 있고 없을수도 있지만 하는게 좋음
③ 결정트리 계열 모델: 스케일링 하는 의미가 없음
따라서 다음과 같은 코드로 registered와 casual을 스케일링해준다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
train['casual_sc'] = scaler.fit_transform(train[['casual']])
train['registered_sc'] = scaler.fit_transform(train[['registered']])그 후 다시 차트를 그려보면 결과는 다음과 같다.

그 후 humidity에 대해서도 차트를 그려보면 다음과 같고 따라서 습도의 경우도 count에 영향을 미치는 요소라고 결정할 수 있다. 왜 그런지에 대해 생각해보면 날씨가 나쁘면(비가 오면) 습도가 높기때문이라고 생각해 볼 수 있기 때문이다.
마지막으로 windseepd에 대해 차트를 그려보면 다음과 같다.

또한 이 windspeed의 경우는 그래프에서도 count와 별로 관계가 없다는 것을 알 수 있지만
(왜냐하면 끝부분에서도 올라갔다 내려갔다를 반복함) 위에 있었던 히트맵에서도
그 상관계수가 크지 않음을 통해 별로 관계가 없음을 알 수 있다.
그 후 train데이터와 test데이터를 iloc를 통해 나눠줄 수 있다.
X_train = all_data[features].iloc[:len(train)]
y_train = train['count']
X_test = all_data[features].iloc[len(train):]
그리고 one-hot encoding을 해줄 수 있는데
이때 one-hot encoding은 범주형 데이터를 수치적으로 해석하지 않도록 이를 행렬로 표현해 주는 것이다.
X_train = pd.get_dummies(X_train)
X_test = pd.get_dummies(X_test)그 후 tqdm이라는 라이브러리를 import하여 학습을 그 성능을 알아볼 수 있다.
또한 여기서 cv=5는 train 데이터를 5개로 나누어 각 구역을 번갈아가면 test데이터로 활용하여 cross check를 할 수 있도록 하는 것이다.
hyperparameter_list = []
n_estimators_list = [200] # 모델 몇개 만들건지?? = 100개 200개 300개
max_features_list = [0.8] # 특성을 몇개 선택할건지? = 20%, 50% 80%
max_depth_list = [5, 15]
for n_estimators in tqdm_notebook(n_estimators_list):
for max_features in tqdm_notebook(max_features_list):
for max_depth in tqdm_notebook(max_depth_list):
rf = RandomForestRegressor(n_estimators=n_estimators,
max_features=max_features,
max_depth=max_depth,
n_jobs=-1, # CPU코어 다 돌릴래
random_state=0)
score = cross_val_score(rf, X_train, y_train,
cv=5).mean()
hyperparameter_list.append({
'n_estimators' : n_estimators,
'max_features' : max_features,
'max_depth' : max_depth,
'score' : score
})이를 통해 가장 높은 성능을 가진 hyperparameter의 조합을 선정하여 이를 바탕으로
학습시킬 수 있다.
'Machine Learning > 머신러닝기반 빅데이터 응용 전문가과정' 카테고리의 다른 글
| 머신러닝기반 빅데이터 응용 전문가과정 - 13 (0) | 2021.04.12 |
|---|---|
| 머신러닝기반 빅데이터 응용 전문가과정 - 12 (0) | 2021.04.12 |
| 머신러닝기반 빅데이터 응용 전문가과정 - 11 (0) | 2021.04.12 |
| 머신러닝기반 빅데이터 응용 전문가과정 - 10 (0) | 2021.04.12 |
| 머신러닝기반 빅데이터 응용 전문가과정 - 9 (0) | 2021.04.12 |

